7. Análise de boas práticas no Serviço de Família Acolhedora (SFA)#
Para qualificar a análise dos dados dois estados foram escolhidos a partir de duas informações: quantidade de famílias acolhedoras aptas ou acolhendo e proporção de crianças/adolescentes acolhidos pelo SFA em relação ao número total de acolhidos.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df_dados_gerais = pd.read_csv('../data/familia_acolhedora/dados_gerais_tratado.csv')
# Criar um dataframe com as unidades de acolhimento
df_unidade_acolhimento = pd.read_csv('../data/unidades_acolhimento/Censo_SUAS_2023_Unidade_Acolhimento_Dados_Gerais.csv', sep=';', encoding='latin1', low_memory=False)
7.1. Análise da proporção de acolhidos na unidade de acolhimento em relação às crianças e aos adolescentes acolhidos por meio do SFA#
df_unidade_acolhimento['NU_IDENTIFICADOR'].apply(type).unique()
array([<class 'int'>], dtype=object)
# Criar uma lista com nomes para as colunas, de forma a compreender melhor os dados
rename_cols_uni = {
'q11':'qtd_pessoas_acolhidas',
'q14_1_1':'qtd_masc_0_2',
'q14_1_2':'qtd_masc_3_5',
'q14_1_3':'qtd_masc_6_11',
'q14_1_4':'qtd_masc_12_13',
'q14_1_5':'qtd_masc_14_15',
'q14_1_6':'qtd_masc_16_17',
'q14_1_7':'qtd_masc_18_21',
'q14_1_8':'qtd_masc_22_59',
'q14_1_9':'qtd_masc_60_79',
'q14_1_10':'qtd_masc_acima_80',
'q14_1_11':'qtd_masc_total',
'q14_2_1':'qtd_fem_0_2',
'q14_2_2':'qtd_fem_3_5',
'q14_2_3':'qtd_fem_6_11',
'q14_2_4':'qtd_fem_12_13',
'q14_2_5':'qtd_fem_14_15',
'q14_2_6':'qtd_fem_16_17',
'q14_2_7':'qtd_fem_18_21',
'q14_2_8':'qtd_fem_22_59',
'q14_2_9':'qtd_fem_60_79',
'q14_2_10':'qtd_fem_acima_80',
'q14_2_11':'qtd_fem_total',
}
# Renomear as colunas do dataframe de unidades de acolhimento de acordo com a lista criada
df_unidade_acolhimento = df_unidade_acolhimento.rename(columns=rename_cols_uni)
# Criar uma lista para filtrar o dataframe de unidades acolhedoras
filter_pessoas_uni = ['NU_IDENTIFICADOR',
'IBGE',
'qtd_pessoas_acolhidas',
'qtd_masc_0_2',
'qtd_masc_3_5',
'qtd_masc_6_11',
'qtd_masc_12_13',
'qtd_masc_14_15',
'qtd_masc_16_17',
'qtd_masc_18_21',
'qtd_masc_22_59',
'qtd_masc_60_79',
'qtd_masc_acima_80',
'qtd_masc_total',
'qtd_fem_0_2',
'qtd_fem_3_5',
'qtd_fem_6_11',
'qtd_fem_12_13',
'qtd_fem_14_15',
'qtd_fem_16_17',
'qtd_fem_18_21',
'qtd_fem_22_59',
'qtd_fem_60_79',
'qtd_fem_acima_80',
'qtd_fem_total']
# Criar um dataframe a partir do filtro de pessoas acolhidas
df_pessoas_uni_acolhi = df_unidade_acolhimento[filter_pessoas_uni]
# As colunas são tipo object o que significa que elas têm tipo string no meio o que vai impactar na soma
print(df_pessoas_uni_acolhi[['NU_IDENTIFICADOR', 'IBGE', 'qtd_pessoas_acolhidas', 'qtd_masc_0_2',
'qtd_masc_3_5', 'qtd_masc_6_11', 'qtd_masc_12_13', 'qtd_masc_14_15',
'qtd_masc_16_17', 'qtd_masc_18_21', 'qtd_masc_22_59', 'qtd_masc_60_79',
'qtd_masc_acima_80', 'qtd_masc_total', 'qtd_fem_0_2', 'qtd_fem_3_5',
'qtd_fem_6_11', 'qtd_fem_12_13', 'qtd_fem_14_15', 'qtd_fem_16_17',
'qtd_fem_18_21', 'qtd_fem_22_59', 'qtd_fem_60_79', 'qtd_fem_acima_80',
'qtd_fem_total']].dtypes)
NU_IDENTIFICADOR int64
IBGE int64
qtd_pessoas_acolhidas object
qtd_masc_0_2 object
qtd_masc_3_5 object
qtd_masc_6_11 object
qtd_masc_12_13 object
qtd_masc_14_15 object
qtd_masc_16_17 object
qtd_masc_18_21 object
qtd_masc_22_59 object
qtd_masc_60_79 object
qtd_masc_acima_80 object
qtd_masc_total object
qtd_fem_0_2 object
qtd_fem_3_5 object
qtd_fem_6_11 object
qtd_fem_12_13 object
qtd_fem_14_15 object
qtd_fem_16_17 object
qtd_fem_18_21 object
qtd_fem_22_59 object
qtd_fem_60_79 object
qtd_fem_acima_80 object
qtd_fem_total object
dtype: object
# Fazer uma cópia explícita do DataFrame
df_pessoas_uni_acolhi = df_pessoas_uni_acolhi.copy()
# Converter colunas para tipo numérico e depois para inteiro
cols_para_converter = [
'qtd_pessoas_acolhidas', 'qtd_masc_0_2',
'qtd_masc_3_5', 'qtd_masc_6_11', 'qtd_masc_12_13', 'qtd_masc_14_15',
'qtd_masc_16_17', 'qtd_masc_18_21', 'qtd_masc_22_59', 'qtd_masc_60_79',
'qtd_masc_acima_80', 'qtd_masc_total', 'qtd_fem_0_2', 'qtd_fem_3_5',
'qtd_fem_6_11', 'qtd_fem_12_13', 'qtd_fem_14_15', 'qtd_fem_16_17',
'qtd_fem_18_21', 'qtd_fem_22_59', 'qtd_fem_60_79', 'qtd_fem_acima_80',
'qtd_fem_total'
]
# Limpeza adicional das colunas
for col in cols_para_converter:
df_pessoas_uni_acolhi[col] = (
df_pessoas_uni_acolhi[col]
.astype(str) # Converter para string
.str.strip() # Remover espaços em branco no início e fim
.str.replace(r'\D', '', regex=True) # Remover qualquer caractere que não seja dígito
.replace('', '0') # Substituir strings vazias por '0'
)
# Converter para numérico e depois para inteiro
df_pessoas_uni_acolhi[cols_para_converter] = (
df_pessoas_uni_acolhi[cols_para_converter]
.apply(pd.to_numeric, errors='coerce')
.fillna(0)
.astype(int)
)
# Verificar os tipos de dados após a conversão
print(df_pessoas_uni_acolhi[cols_para_converter].dtypes)
qtd_pessoas_acolhidas int64
qtd_masc_0_2 int64
qtd_masc_3_5 int64
qtd_masc_6_11 int64
qtd_masc_12_13 int64
qtd_masc_14_15 int64
qtd_masc_16_17 int64
qtd_masc_18_21 int64
qtd_masc_22_59 int64
qtd_masc_60_79 int64
qtd_masc_acima_80 int64
qtd_masc_total int64
qtd_fem_0_2 int64
qtd_fem_3_5 int64
qtd_fem_6_11 int64
qtd_fem_12_13 int64
qtd_fem_14_15 int64
qtd_fem_16_17 int64
qtd_fem_18_21 int64
qtd_fem_22_59 int64
qtd_fem_60_79 int64
qtd_fem_acima_80 int64
qtd_fem_total int64
dtype: object
df_pessoas_uni_acolhi = df_pessoas_uni_acolhi.copy()
# Criar a coluna 'qtd_masc_acima_18' somando as faixas etárias acima de 18 anos para masculino
df_pessoas_uni_acolhi['qtd_masc_acima_18'] = (
df_pessoas_uni_acolhi[['qtd_masc_18_21', 'qtd_masc_22_59', 'qtd_masc_60_79', 'qtd_masc_acima_80']]
.sum(axis=1)
)
# Criar a coluna 'qtd_fem_acima_18' somando as faixas etárias acima de 18 anos para feminino
df_pessoas_uni_acolhi['qtd_fem_acima_18'] = (
df_pessoas_uni_acolhi[['qtd_fem_18_21', 'qtd_fem_22_59', 'qtd_fem_60_79', 'qtd_fem_acima_80']]
.sum(axis=1)
)
# Criar uma cópia explícita para evitar o SettingWithCopyWarning
df_verificacao = df_pessoas_uni_acolhi[['qtd_masc_18_21', 'qtd_masc_22_59', 'qtd_masc_60_79', 'qtd_masc_acima_80', 'qtd_masc_acima_18']].copy()
# Calcular a soma manualmente usando .loc[]
df_verificacao.loc[:, 'soma_manual'] = df_verificacao[['qtd_masc_18_21', 'qtd_masc_22_59', 'qtd_masc_60_79', 'qtd_masc_acima_80']].sum(axis=1)
# Calcular a diferença usando .loc[]
df_verificacao.loc[:, 'diferenca'] = df_verificacao['qtd_masc_acima_18'] - df_verificacao['soma_manual']
print(df_pessoas_uni_acolhi.columns.tolist())
['NU_IDENTIFICADOR', 'IBGE', 'qtd_pessoas_acolhidas', 'qtd_masc_0_2', 'qtd_masc_3_5', 'qtd_masc_6_11', 'qtd_masc_12_13', 'qtd_masc_14_15', 'qtd_masc_16_17', 'qtd_masc_18_21', 'qtd_masc_22_59', 'qtd_masc_60_79', 'qtd_masc_acima_80', 'qtd_masc_total', 'qtd_fem_0_2', 'qtd_fem_3_5', 'qtd_fem_6_11', 'qtd_fem_12_13', 'qtd_fem_14_15', 'qtd_fem_16_17', 'qtd_fem_18_21', 'qtd_fem_22_59', 'qtd_fem_60_79', 'qtd_fem_acima_80', 'qtd_fem_total', 'qtd_masc_acima_18', 'qtd_fem_acima_18']
colunas_para_remover = [
'NU_IDENTIFICADOR', 'qtd_masc_18_21', 'qtd_masc_22_59', 'qtd_masc_60_79',
'qtd_masc_acima_80', 'qtd_fem_18_21', 'qtd_fem_22_59', 'qtd_fem_60_79', 'qtd_fem_acima_80'
]
# Verificar quais colunas estão ausentes
colunas_existentes = [col for col in colunas_para_remover if col in df_pessoas_uni_acolhi.columns]
colunas_ausentes = [col for col in colunas_para_remover if col not in df_pessoas_uni_acolhi.columns]
print("Colunas existentes:", colunas_existentes)
print("Colunas ausentes:", colunas_ausentes)
Colunas existentes: ['NU_IDENTIFICADOR', 'qtd_masc_18_21', 'qtd_masc_22_59', 'qtd_masc_60_79', 'qtd_masc_acima_80', 'qtd_fem_18_21', 'qtd_fem_22_59', 'qtd_fem_60_79', 'qtd_fem_acima_80']
Colunas ausentes: []
df_pessoas_uni_acolhi = df_pessoas_uni_acolhi.drop(columns=colunas_existentes)
df_dados_gerais['qtd_fem_total'] = df_dados_gerais[['qtd_fem_0_2',
'qtd_fem_3_5',
'qtd_fem_6_11',
'qtd_fem_12_13',
'qtd_fem_14_15',
'qtd_fem_16_17',
'qtd_fem_acima_18']].sum(axis=1)
# Criar uma lista para filtrar o dataframe de famílias acolhedoras (dados_gerais)
filter_fam = ['NU_IDENTIFICADOR',
'IBGE',
'qtd_criancas_acolhidas',
'qtd_masc_0_2',
'qtd_masc_3_5',
'qtd_masc_6_11',
'qtd_masc_12_13',
'qtd_masc_14_15',
'qtd_masc_16_17',
'qtd_masc_acima_18',
'qtd_masc_total',
'qtd_fem_0_2',
'qtd_fem_3_5',
'qtd_fem_6_11',
'qtd_fem_12_13',
'qtd_fem_14_15',
'qtd_fem_16_17',
'qtd_fem_acima_18',
'qtd_fem_total',
]
# Verificou-se que a coluna NU_IDENTIFICADOR - que serve de link para as demais tabelas do Censo - no dataframe de dados gerais está como string (texto)
df_dados_gerais['NU_IDENTIFICADOR'].apply(type).unique()
array([<class 'str'>], dtype=object)
# Criar um regex para retirar espaços vazios e as vírgulas para transformar a coluna em tipo inteiro
df_dados_gerais['NU_IDENTIFICADOR'] = df_dados_gerais['NU_IDENTIFICADOR'].str.replace(',', '.', regex=False).astype(float).astype(int)
print(df_dados_gerais[['NU_IDENTIFICADOR', 'IBGE', 'qtd_criancas_acolhidas', 'qtd_masc_0_2',
'qtd_masc_3_5', 'qtd_masc_6_11', 'qtd_masc_12_13', 'qtd_masc_14_15',
'qtd_masc_16_17', 'qtd_masc_acima_18', 'qtd_masc_total', 'qtd_fem_0_2',
'qtd_fem_3_5', 'qtd_fem_6_11', 'qtd_fem_12_13', 'qtd_fem_14_15',
'qtd_fem_16_17', 'qtd_fem_acima_18', 'qtd_fem_total']].dtypes)
NU_IDENTIFICADOR int64
IBGE int64
qtd_criancas_acolhidas int64
qtd_masc_0_2 int64
qtd_masc_3_5 int64
qtd_masc_6_11 int64
qtd_masc_12_13 int64
qtd_masc_14_15 int64
qtd_masc_16_17 int64
qtd_masc_acima_18 int64
qtd_masc_total int64
qtd_fem_0_2 int64
qtd_fem_3_5 int64
qtd_fem_6_11 int64
qtd_fem_12_13 int64
qtd_fem_14_15 int64
qtd_fem_16_17 int64
qtd_fem_acima_18 int64
qtd_fem_total int64
dtype: object
df_qtd_total_uni = df_pessoas_uni_acolhi.groupby('IBGE', as_index=False)[['qtd_pessoas_acolhidas', 'qtd_masc_total', 'qtd_fem_total']].sum()
df_qtd_uni_munic = df_qtd_total_uni[df_qtd_total_uni['IBGE'].between(100000, 999999)]
# Carregar os dados de município de acordo com o código do IBGE
df_municipios = pd.read_excel('../data/dados_geo/RELATORIO_DTB_BRASIL_MUNICIPIO.xls', header=6, engine='xlrd')
WARNING *** OLE2 inconsistency: SSCS size is 0 but SSAT size is non-zero
*** No CODEPAGE record, no encoding_override: will use 'iso-8859-1'
# Fazer uma cópia explícita do DataFrame
df_qtd_uni_munic = df_qtd_uni_munic.copy()
# Padronizar a coluna IBGE no DataFrame 'df_qtd_total_municipios' para ter seis dígitos
df_qtd_uni_munic['IBGE'] = df_qtd_uni_munic['IBGE'].astype(str).str.zfill(6)
# Remover o dígito verificador (último dígito) da coluna 'Código Município Completo' no DataFrame 'municipios'
df_municipios['Código Município Completo'] = df_municipios['Código Município Completo'].astype(str).str[:-1]
# Padronizar para seis dígitos
df_municipios['Código Município Completo'] = df_municipios['Código Município Completo'].str.zfill(6)
# Realizar o merge entre os DataFrames
df_qtd_uni_municipios = pd.merge(
df_qtd_uni_munic,
df_municipios[['Nome_UF', 'Código Município Completo', 'Nome_Município']],
left_on='IBGE',
right_on='Código Município Completo',
how='inner'
)
# Selecionar as colunas desejadas
df_qtd_uni_municipios = df_qtd_uni_municipios[['IBGE', 'Nome_Município', 'Nome_UF', 'qtd_pessoas_acolhidas', 'qtd_masc_total', 'qtd_fem_total']]
df_qtd_total_fam = df_dados_gerais.groupby('IBGE', as_index=False)[['qtd_criancas_acolhidas', 'qtd_masc_total', 'qtd_fem_total']].sum()
df_qtd_total_fam_munic = df_qtd_total_fam[df_qtd_total_fam['IBGE'].between(100000, 999999)]
# Fazer uma cópia explícita do DataFrame
df_qtd_total_fam_munic = df_qtd_total_fam_munic.copy()
# Padronizar a coluna IBGE no DataFrame 'df_qtd_total_municipios' para ter seis dígitos
df_qtd_total_fam_munic['IBGE'] = df_qtd_total_fam_munic['IBGE'].astype(str).str.zfill(6)
# Realizar o merge entre os DataFrames
df_qtd_fam_municipios = pd.merge(
df_qtd_total_fam_munic,
df_municipios[['Nome_UF', 'Código Município Completo', 'Nome_Município']],
left_on='IBGE',
right_on='Código Município Completo',
how='inner'
)
# Selecionar as colunas desejadas
df_qtd_fam_municipios = df_qtd_fam_municipios[['IBGE', 'Nome_Município', 'Nome_UF', 'qtd_criancas_acolhidas', 'qtd_masc_total', 'qtd_fem_total']]
# Aqui dá pra perceber que a quantidade de municípios é diferente nos dois dataframes
print(df_qtd_uni_municipios.shape)
print(df_qtd_fam_municipios.shape)
(2278, 6)
(584, 6)
# Realizar o merge
df_uni_fam_munic = pd.merge(df_qtd_uni_municipios, df_qtd_fam_municipios,
on=['IBGE', 'Nome_Município', 'Nome_UF'],
how='left',
suffixes=('_unidades', '_familia'))
# Preencher valores nulos com zero
df_uni_fam_munic.fillna(0, inplace=True)
# Criar a variável pct_acolhidas_fam: percentual total de pessoas acolhidas pelo Família Acolhedora
df_uni_fam_munic['pct_total_acolhidos_fam'] = df_uni_fam_munic['qtd_criancas_acolhidas'] / df_uni_fam_munic['qtd_pessoas_acolhidas']
# Criar a variável pct_masc_acolhidos_fam: percentual total de meninos/homens acolhidos pelo Família Acolhedora
df_uni_fam_munic['pct_masc_acolhidos_fam'] = df_uni_fam_munic['qtd_masc_total_familia'] / df_uni_fam_munic['qtd_masc_total_unidades']
# Criar a variável pct_fem_acolhidas_fam: percentual total de meninas/mulheres acolhidas pelo Família Acolhedora
df_uni_fam_munic['pct_fem_acolhidas_fam'] = df_uni_fam_munic['qtd_fem_total_familia'] / df_uni_fam_munic['qtd_fem_total_unidades']
# Substituir valores infinitos (resultado de divisão por zero) por zero
df_uni_fam_munic.replace([float('inf'), -float('inf')], 0, inplace=True)
df_uni_fam_munic.head()
| IBGE | Nome_Município | Nome_UF | qtd_pessoas_acolhidas | qtd_masc_total_unidades | qtd_fem_total_unidades | qtd_criancas_acolhidas | qtd_masc_total_familia | qtd_fem_total_familia | pct_total_acolhidos_fam | pct_masc_acolhidos_fam | pct_fem_acolhidas_fam | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 110001 | Alta Floresta D'Oeste | Rondônia | 6 | 4 | 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 110002 | Ariquemes | Rondônia | 66 | 39 | 27 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 110003 | Cabixi | Rondônia | 4 | 2 | 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 110004 | Cacoal | Rondônia | 91 | 67 | 24 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 110005 | Cerejeiras | Rondônia | 4 | 3 | 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
# Agrupar os dados por UF e calcular as somas
df_uf_acolhimento = df_uni_fam_munic.groupby('Nome_UF').agg({
'qtd_pessoas_acolhidas': 'sum',
'qtd_criancas_acolhidas': 'sum'
}).reset_index()
# Calcular a proporção total de acolhimento pelo Família Acolhedora para cada UF
df_uf_acolhimento['pct_total_acolhidos_fam'] = df_uf_acolhimento['qtd_criancas_acolhidas'] / df_uf_acolhimento['qtd_pessoas_acolhidas']
df_uf_acolhimento.sort_values(by='pct_total_acolhidos_fam', ascending=False)
| Nome_UF | qtd_pessoas_acolhidas | qtd_criancas_acolhidas | pct_total_acolhidos_fam | |
|---|---|---|---|---|
| 3 | Amazonas | 607 | 36.0 | 0.059308 |
| 13 | Paraná | 10775 | 510.0 | 0.047332 |
| 23 | Santa Catarina | 4534 | 141.0 | 0.031098 |
| 11 | Mato Grosso do Sul | 2932 | 61.0 | 0.020805 |
| 9 | Maranhão | 538 | 11.0 | 0.020446 |
| 6 | Distrito Federal | 1660 | 28.0 | 0.016867 |
| 20 | Rio de Janeiro | 8189 | 129.0 | 0.015753 |
| 14 | Paraíba | 1016 | 16.0 | 0.015748 |
| 17 | Piauí | 640 | 9.0 | 0.014063 |
| 5 | Ceará | 2077 | 29.0 | 0.013962 |
| 0 | Acre | 680 | 9.0 | 0.013235 |
| 19 | Rio Grande do Sul | 10105 | 129.0 | 0.012766 |
| 21 | Rondônia | 799 | 10.0 | 0.012516 |
| 12 | Minas Gerais | 26880 | 292.0 | 0.010863 |
| 15 | Pará | 1760 | 16.0 | 0.009091 |
| 16 | Pernambuco | 2444 | 20.0 | 0.008183 |
| 7 | Espírito Santo | 2644 | 18.0 | 0.006808 |
| 18 | Rio Grande do Norte | 1093 | 7.0 | 0.006404 |
| 26 | Tocantins | 350 | 2.0 | 0.005714 |
| 2 | Amapá | 185 | 1.0 | 0.005405 |
| 25 | São Paulo | 51143 | 256.0 | 0.005006 |
| 10 | Mato Grosso | 2462 | 11.0 | 0.004468 |
| 4 | Bahia | 5958 | 16.0 | 0.002685 |
| 8 | Goiás | 6132 | 8.0 | 0.001305 |
| 1 | Alagoas | 1426 | 0.0 | 0.000000 |
| 22 | Roraima | 42 | 0.0 | 0.000000 |
| 24 | Sergipe | 761 | 0.0 | 0.000000 |
7.2. Análise dos estados com maior proporção de acolhidos no SFA e maior quantidade de famílias acolhedoras#
Para evidenciar e analisar boas práticas, primeiro analisamos as quatro primeiras posições, em ordem decrescente, da quantidade de famílias acolhendo ou aptas a acolher conforme variável ‘qtd_fam_aptas_ou_acolhendo’. Os seguintes estados, por ordem decrescente, foram selecionados:
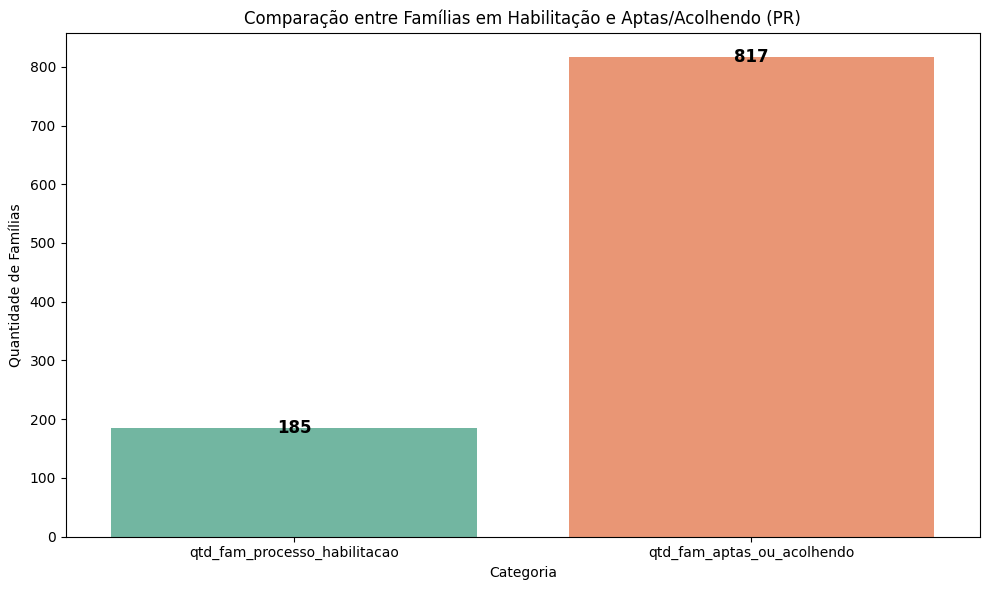
Paraná (PR): 817
Minas Gerais (MG): 522
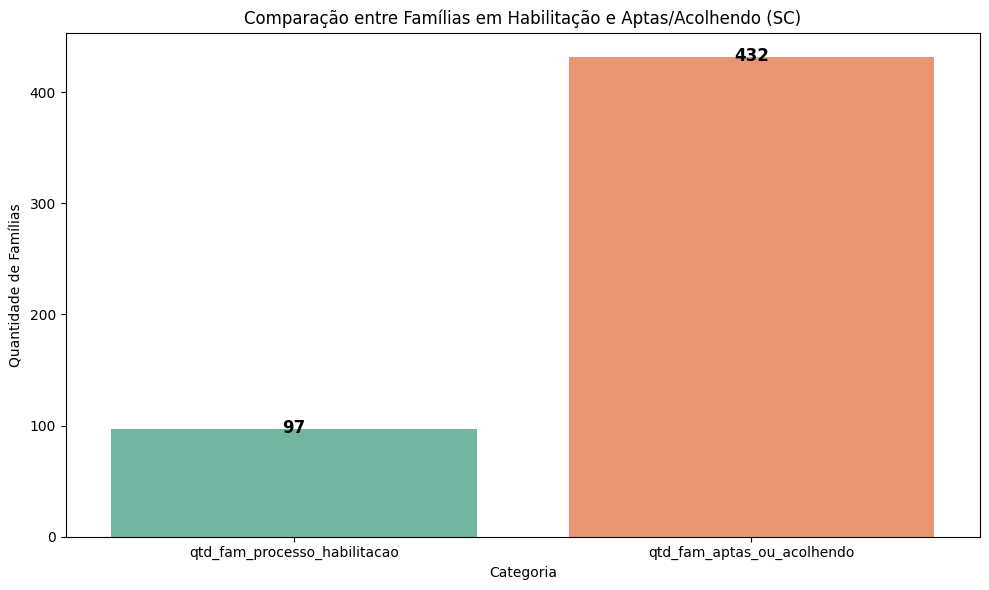
Santa Catarina (SC): 432
São Paulo (SP): 410
Observando os números dos estados acima, é possível identificar uma diferença significativa entre SP e o quinto colocado (Rio de Janeiro com 200 famílias), portanto, pela disparidade de quantidade, apenas os 4 primeiros foram selecionados.
Ao ordenarmos as cinco maiores proporções de acolhidos no SFA em relação ao total de acolhidos por UF, chegamos aos seguintes estados:
Amazonas (AM): 0.059%
Paraná (PR): 0.046%
Santa Catarina (SC): 0.031%
Mato Grosso do Sul (MS): 0.020%
Maranhão (MA): 0.020%
A partir dessas duas listas, selecionamos os estados do Paraná (PR) e de Santa Catarina (SC) por configurarem em ambas as listas dos maiores quantitativos, assim, é possível identificar padrões, ações ou perfis desses estados que possam nos orientar a ter um diagnóstico de práticas que consolidam os números relacionados aos quantitativos de famílias e de crianças e adolescentes acolhidos e de porcentagem de acolhidos em relação ao total de acolhidos por UF.
7.2.1. Subsídio mensal#
# Transformar os dados em números
df_dados_gerais['subsidio_valor_mensal'] = pd.to_numeric(df_dados_gerais['subsidio_valor_mensal'], errors='coerce')
# Criar um dataframe apenas com as observações do Paraná
df_pr = df_dados_gerais[df_dados_gerais['uf'] == 'PR']
df_pr.shape
(131, 175)
# Criar um dataframe apenas com as observações de Santa Catarina
df_sc = df_dados_gerais[df_dados_gerais['uf'] == 'SC']
df_sc.shape
(105, 175)
df_pr = df_pr.copy()
df_sc = df_sc.copy()
df_pr['subsidio_valor_mensal'].fillna(0, inplace=True)
df_sc['subsidio_valor_mensal'].fillna(0, inplace=True)
/tmp/ipykernel_2173/4234166614.py:4: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
df_pr['subsidio_valor_mensal'].fillna(0, inplace=True)
/tmp/ipykernel_2173/4234166614.py:5: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
df_sc['subsidio_valor_mensal'].fillna(0, inplace=True)
# Calcular os quartis e o intervalo interquartil (IQR)
q1 = df_dados_gerais['subsidio_valor_mensal'].quantile(0.25)
q3 = df_dados_gerais['subsidio_valor_mensal'].quantile(0.75)
iqr = q3 - q1
# Determinar o limite superior para outliers
limite_superior = q3 + 1.5 * iqr
# Filtrar os outliers
outliers = df_dados_gerais[df_dados_gerais['subsidio_valor_mensal'] > limite_superior]
# Exibir o limite superior para referência
print(f"Limite superior para outliers: {limite_superior}")
Limite superior para outliers: 1350.0
# Filtrar para manter apenas valores iguais ou abaixo de 13000
df_sem_outliers_pr = df_pr[df_pr['subsidio_valor_mensal'] < 13000]
df_sem_outliers_sc = df_sc[df_sc['subsidio_valor_mensal'] < 13000]
estatisticas_pr = df_sem_outliers_pr['subsidio_valor_mensal'].describe()
print("Estatísticas descritivas para PR:")
print(estatisticas_pr)
Estatísticas descritivas para PR:
count 130.000000
mean 1195.407692
std 480.815001
min 0.000000
25% 1320.000000
50% 1320.000000
75% 1320.000000
max 2369.000000
Name: subsidio_valor_mensal, dtype: float64
df_zero_subsidio_pr = df_sem_outliers_pr[df_sem_outliers_pr['subsidio_valor_mensal'] == 0]
df_zero_subsidio_pr.shape
(14, 175)
estatisticas_sc = df_sem_outliers_sc['subsidio_valor_mensal'].describe()
print("Estatísticas descritivas para SC:")
print(estatisticas_sc)
Estatísticas descritivas para SC:
count 104.000000
mean 1334.490385
std 538.056174
min 0.000000
25% 1320.000000
50% 1320.000000
75% 1320.000000
max 2640.000000
Name: subsidio_valor_mensal, dtype: float64
df_zero_subsidio_sc = df_sem_outliers_sc[df_sem_outliers_sc['subsidio_valor_mensal'] == 0]
df_zero_subsidio_sc.shape
(9, 175)
# Criar um histograma com KDE para visualizar a frequência e o formato da distribuição dos valores do PR
plt.figure(figsize=(10, 6))
sns.histplot(
data=df_sem_outliers_pr,
x='subsidio_valor_mensal',
kde=True,
bins=15,
color='blue',
alpha=0.7
)
# Configurar o gráfico
plt.title('Distribuição de Frequência dos Subsídios Mensais (PR)')
plt.xlabel('Subsídio Mensal (R$)')
plt.ylabel('Frequência')
plt.tight_layout()
plt.show()
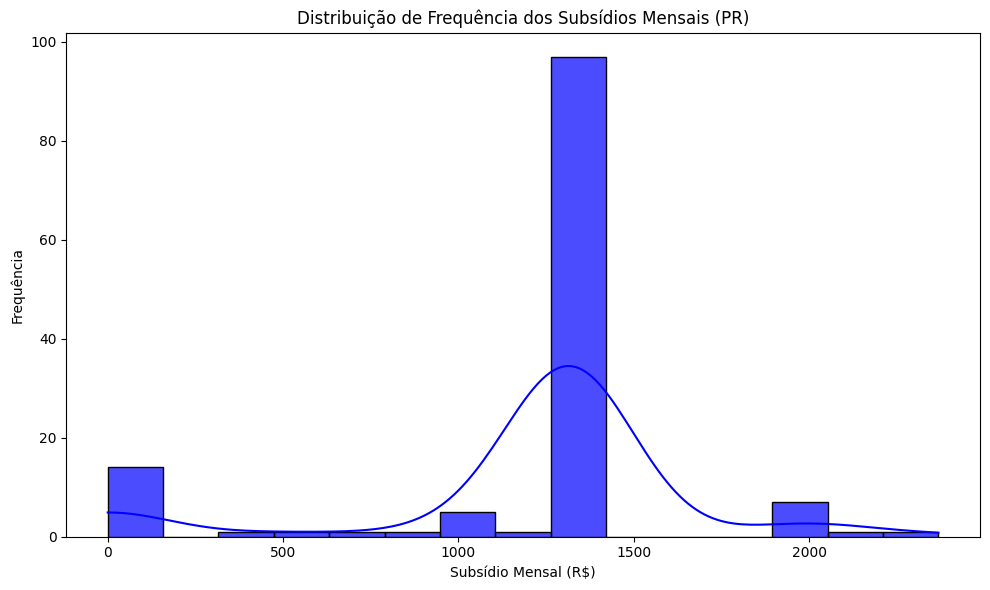
# Criar um histograma com KDE para visualizar a frequência e o formato da distribuição dos valores do SC
plt.figure(figsize=(10, 6))
sns.histplot(
data=df_sem_outliers_sc,
x='subsidio_valor_mensal',
kde=True,
bins=15,
color='blue',
alpha=0.7
)
# Configurar o gráfico
plt.title('Distribuição de Frequência dos Subsídios Mensais (SC)')
plt.xlabel('Subsídio Mensal (R$)')
plt.ylabel('Frequência')
plt.tight_layout()
plt.show()

7.2.2. Comparação entre famílias em processo de habilitação e famílias aptas ou acolhendo#
# Selecionar as colunas relevantes
df_pr_agrupado = df_pr[['qtd_fam_processo_habilitacao', 'qtd_fam_aptas_ou_acolhendo']].sum().reset_index()
df_pr_agrupado.columns = ['Categoria', 'Quantidade']
# Gráfico de barras para o Paraná
plt.figure(figsize=(10, 6))
ax = sns.barplot(x='Categoria', y='Quantidade', data=df_pr_agrupado, palette='Set2', hue='Categoria', legend=False)
# Adicionando os valores dentro das barras
for p in ax.patches:
ax.text(
p.get_x() + p.get_width() / 2, # Coordenada X (meio da barra)
p.get_height() + 0.5, # Coordenada Y (acima da barra)
int(p.get_height()), # Valor a ser exibido
ha='center', # Centralizar o texto horizontalmente
va='center', # Centralizar o texto verticalmente
fontsize=12, # Tamanho da fonte
color='black', # Cor do texto
weight='bold' # Negrito
)
# Adicionando título e rótulos
plt.title('Comparação entre Famílias em Habilitação e Aptas/Acolhendo (PR)')
plt.xlabel('Categoria')
plt.ylabel('Quantidade de Famílias')
# Exibindo o gráfico
plt.tight_layout()
plt.show()
# Selecionar as colunas relevantes
df_sc_agrupado = df_sc[['qtd_fam_processo_habilitacao', 'qtd_fam_aptas_ou_acolhendo']].sum().reset_index()
df_sc_agrupado.columns = ['Categoria', 'Quantidade']
# Gráfico de barras para Santa Catarina
plt.figure(figsize=(10, 6))
ax = sns.barplot(x='Categoria', y='Quantidade', data=df_sc_agrupado, palette='Set2', hue='Categoria', legend=False)
# Adicionando os valores dentro das barras
for p in ax.patches:
ax.text(
p.get_x() + p.get_width() / 2, # Coordenada X (meio da barra)
p.get_height() + 0.5, # Coordenada Y (acima da barra)
int(p.get_height()), # Valor a ser exibido
ha='center', # Centralizar o texto horizontalmente
va='center', # Centralizar o texto verticalmente
fontsize=12, # Tamanho da fonte
color='black', # Cor do texto
weight='bold' # Negrito
)
# Adicionando título e rótulos
plt.title('Comparação entre Famílias em Habilitação e Aptas/Acolhendo (SC)')
plt.xlabel('Categoria')
plt.ylabel('Quantidade de Famílias')
# Exibindo o gráfico
plt.tight_layout()
plt.show()
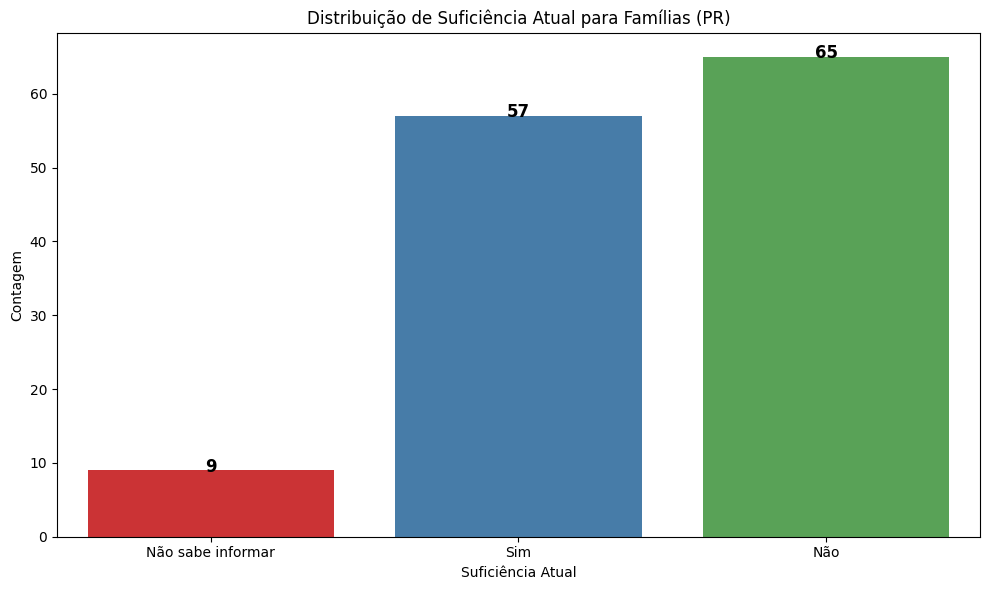
7.2.3. Quantidade de famílias acolhendo é suficiente para a demanda do SFA#
# Agrupando os dados para PR
df_agrupado_suficiente_pr = (
df_pr.groupby(['num_atual_fam_suficiente'])
.size()
.reset_index(name='contagem')
.sort_values(by='contagem', ascending=True) # Ordenar em ordem crescente
)
# Plotando o gráfico de barras para PR
plt.figure(figsize=(10, 6))
ax = sns.barplot(
x='num_atual_fam_suficiente',
y='contagem',
data=df_agrupado_suficiente_pr,
palette='Set1',
hue='num_atual_fam_suficiente',
legend=False
)
# Adicionando os valores dentro das barras
for p in ax.patches:
ax.text(
p.get_x() + p.get_width() / 2, # Coordenada X (meio da barra)
p.get_height() + 0.5, # Coordenada Y (acima da barra)
int(p.get_height()), # Valor a ser exibido
ha='center', # Centralizar o texto horizontalmente
va='center', # Centralizar o texto verticalmente
fontsize=12, # Tamanho da fonte
color='black', # Cor do texto
weight='bold' # Negrito
)
# Adicionando título e rótulos
plt.title('Distribuição de Suficiência Atual para Famílias (PR)')
plt.xlabel('Suficiência Atual')
plt.ylabel('Contagem')
# Exibindo o gráfico
plt.tight_layout()
plt.show()
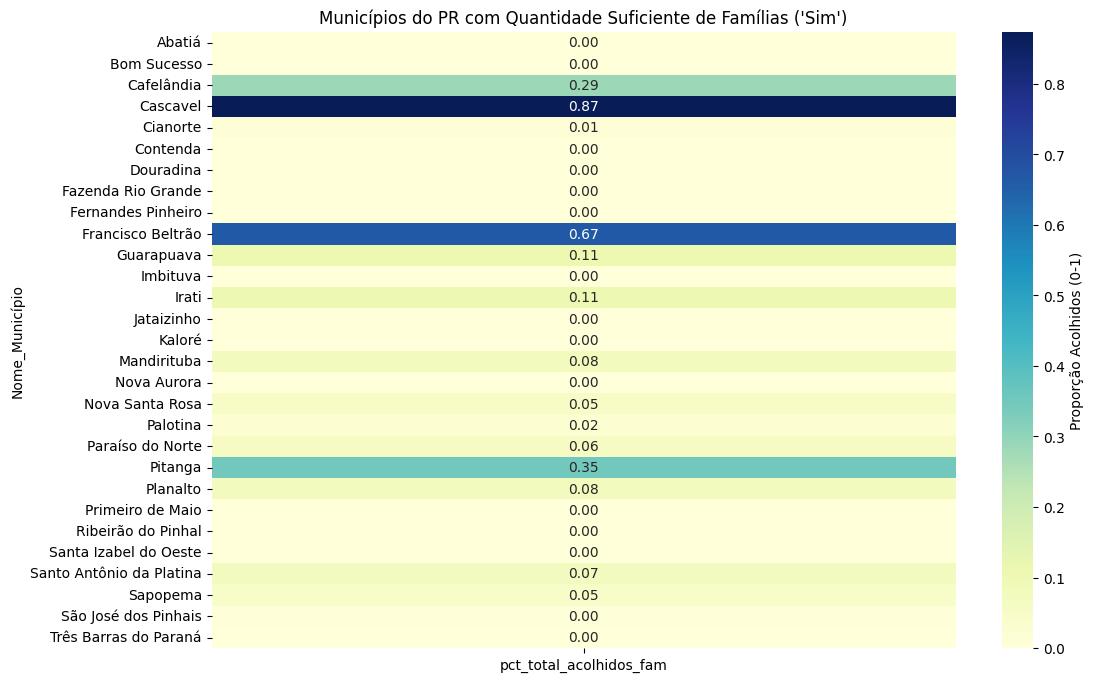
df_uni_fam_munic_pr = df_uni_fam_munic[df_uni_fam_munic['Nome_UF'] == 'Paraná']
# Selecionar as colunas relevantes para o merge
df_pr_reduzido = df_pr[['IBGE', 'num_atual_fam_suficiente']]
df_uni_reduzido_pr = df_uni_fam_munic_pr[['IBGE', 'Nome_Município', 'pct_total_acolhidos_fam']]
# Fazer cópias explícitas dos DataFrames
df_pr_reduzido = df_pr_reduzido.copy()
df_uni_reduzido_pr = df_uni_reduzido_pr.copy()
# Converter as colunas 'IBGE' para string
df_pr_reduzido['IBGE'] = df_pr_reduzido['IBGE'].astype(str)
df_uni_reduzido_pr['IBGE'] = df_uni_reduzido_pr['IBGE'].astype(str)
# Realizar o merge com base no código IBGE
df_merge_pr = pd.merge(
df_pr_reduzido,
df_uni_reduzido_pr,
on='IBGE',
how='inner'
)
df_merge_pr.head()
| IBGE | num_atual_fam_suficiente | Nome_Município | pct_total_acolhidos_fam | |
|---|---|---|---|---|
| 0 | 410010 | Sim | Abatiá | 0.000000 |
| 1 | 410040 | Não | Almirante Tamandaré | 0.489796 |
| 2 | 410050 | Não sabe informar | Altônia | 0.057143 |
| 3 | 410080 | Não | Alvorada do Sul | 0.000000 |
| 4 | 410110 | Não sabe informar | Andirá | 0.000000 |
# Filtrar o DataFrame para as respostas "Sim" e "Não"
df_sim_pr = df_merge_pr[df_merge_pr['num_atual_fam_suficiente'] == 'Sim']
df_nao_pr = df_merge_pr[df_merge_pr['num_atual_fam_suficiente'] == 'Não']
# Configurar o tamanho do gráfico
plt.figure(figsize=(12, 8))
# Heatmap para "Sim"
plt.title("Municípios do PR com Quantidade Suficiente de Famílias ('Sim')")
sns.heatmap(
df_sim_pr.pivot_table(
index='Nome_Município',
values='pct_total_acolhidos_fam',
aggfunc='mean'
),
annot=True,
cmap="YlGnBu",
fmt=".2f",
cbar_kws={'label': 'Proporção Acolhidos (0-1)'}
)
<Axes: title={'center': "Municípios do PR com Quantidade Suficiente de Famílias ('Sim')"}, ylabel='Nome_Município'>
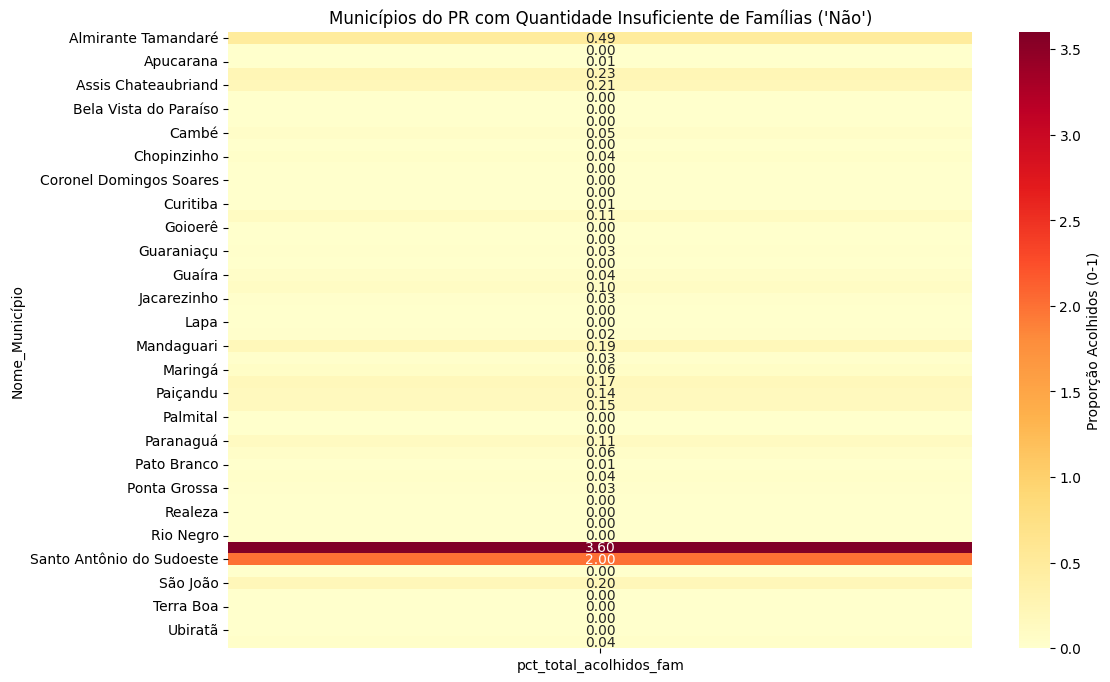
# Configurar o tamanho do gráfico
plt.figure(figsize=(12, 8))
# Heatmap para "Não"
plt.title("Municípios do PR com Quantidade Insuficiente de Famílias ('Não')")
sns.heatmap(
df_nao_pr.pivot_table(
index='Nome_Município',
values='pct_total_acolhidos_fam',
aggfunc='mean'
),
annot=True,
cmap="YlOrRd",
fmt=".2f",
cbar_kws={'label': 'Proporção Acolhidos (0-1)'}
)
plt.show()
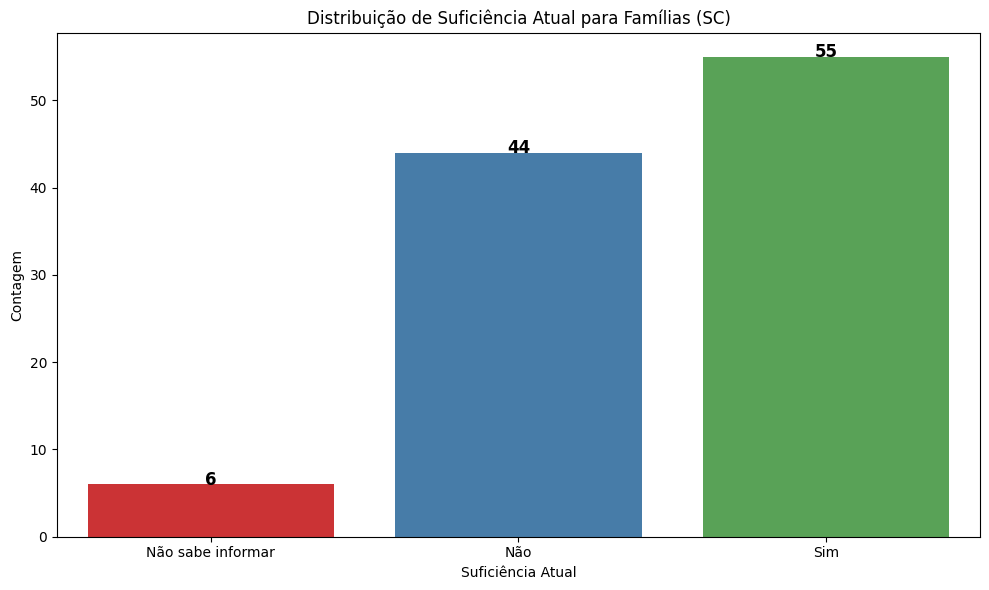
# Agrupando os dados para SC
df_agrupado_suficiente_sc = (
df_sc.groupby(['num_atual_fam_suficiente'])
.size()
.reset_index(name='contagem')
.sort_values(by='contagem', ascending=True) # Ordenar em ordem crescente
)
# Plotando o gráfico de barras para SC
plt.figure(figsize=(10, 6))
ax = sns.barplot(
x='num_atual_fam_suficiente',
y='contagem',
data=df_agrupado_suficiente_sc,
palette='Set1',
hue='num_atual_fam_suficiente',
legend=False
)
# Adicionando os valores dentro das barras
for p in ax.patches:
ax.text(
p.get_x() + p.get_width() / 2, # Coordenada X (meio da barra)
p.get_height() + 0.5, # Coordenada Y (acima da barra)
int(p.get_height()), # Valor a ser exibido
ha='center', # Centralizar o texto horizontalmente
va='center', # Centralizar o texto verticalmente
fontsize=12, # Tamanho da fonte
color='black', # Cor do texto
weight='bold' # Negrito
)
# Adicionando título e rótulos
plt.title('Distribuição de Suficiência Atual para Famílias (SC)')
plt.xlabel('Suficiência Atual')
plt.ylabel('Contagem')
# Exibindo o gráfico
plt.tight_layout()
plt.show()
df_uni_fam_munic_sc = df_uni_fam_munic[df_uni_fam_munic['Nome_UF'] == 'Santa Catarina']
# Selecionar as colunas relevantes para o merge
df_sc_reduzido = df_sc[['IBGE', 'num_atual_fam_suficiente']]
df_uni_reduzido_sc = df_uni_fam_munic_sc[['IBGE', 'Nome_Município', 'pct_total_acolhidos_fam']]
# Fazer cópias explícitas dos DataFrames
df_sc_reduzido = df_sc_reduzido.copy()
df_uni_reduzido_sc = df_uni_reduzido_sc.copy()
# Converter as colunas 'IBGE' para string
df_sc_reduzido['IBGE'] = df_sc_reduzido['IBGE'].astype(str)
df_uni_reduzido_sc['IBGE'] = df_uni_reduzido_sc['IBGE'].astype(str)
# Realizar o merge com base no código IBGE
df_merge_sc = pd.merge(
df_sc_reduzido,
df_uni_reduzido_sc,
on='IBGE',
how='inner'
)
df_merge_sc.head()
| IBGE | num_atual_fam_suficiente | Nome_Município | pct_total_acolhidos_fam | |
|---|---|---|---|---|
| 0 | 420010 | Sim | Abelardo Luz | 0.300000 |
| 1 | 420240 | Não | Blumenau | 0.039007 |
| 2 | 420290 | Não | Brusque | 0.005348 |
| 3 | 420300 | Sim | Caçador | 0.567568 |
| 4 | 420370 | Não | Canelinha | 0.000000 |
# Filtrar o DataFrame para as respostas "Sim" e "Não"
df_sim_sc = df_merge_sc[df_merge_sc['num_atual_fam_suficiente'] == 'Sim']
df_nao_sc = df_merge_sc[df_merge_sc['num_atual_fam_suficiente'] == 'Não']
# Configurar o tamanho do gráfico
plt.figure(figsize=(12, 8))
# Heatmap para "Sim"
plt.title("Municípios de SC com Quantidade Suficiente de Famílias ('Sim')")
sns.heatmap(
df_sim_sc.pivot_table(
index='Nome_Município',
values='pct_total_acolhidos_fam',
aggfunc='mean'
),
annot=True,
cmap="YlGnBu",
fmt=".2f",
cbar_kws={'label': 'Proporção Acolhidos (0-1)'}
)
<Axes: title={'center': "Municípios de SC com Quantidade Suficiente de Famílias ('Sim')"}, ylabel='Nome_Município'>

# Configurar o tamanho do gráfico
plt.figure(figsize=(12, 8))
# Heatmap para "Não"
plt.title("Municípios de SC com Quantidade Insuficiente de Famílias ('Não')")
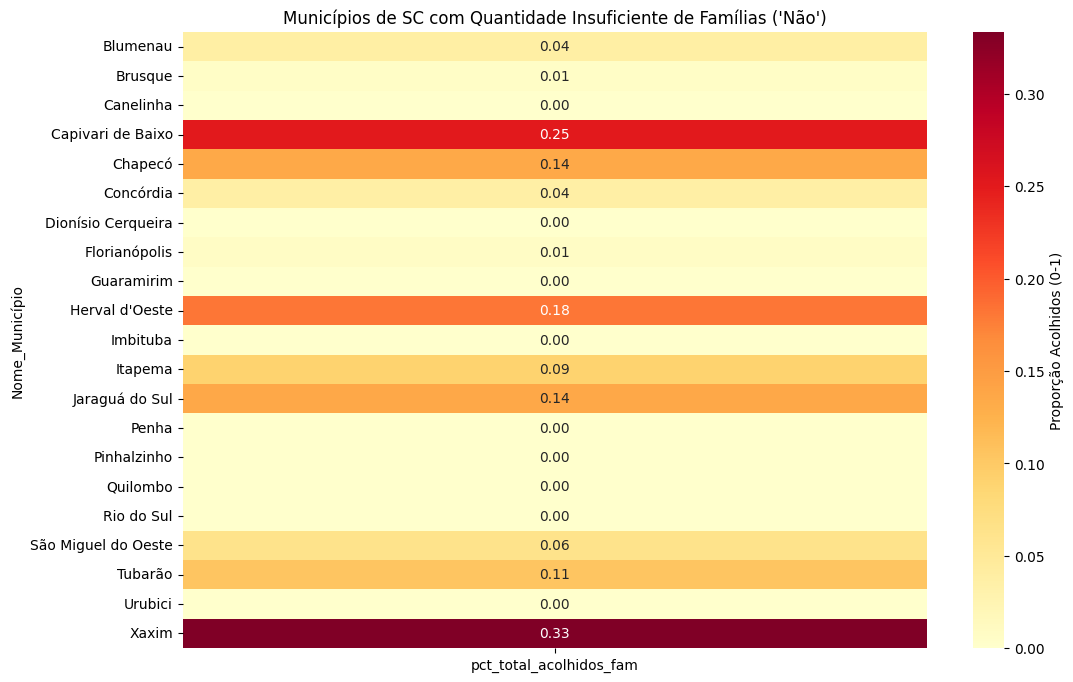
sns.heatmap(
df_nao_sc.pivot_table(
index='Nome_Município',
values='pct_total_acolhidos_fam',
aggfunc='mean'
),
annot=True,
cmap="YlOrRd",
fmt=".2f",
cbar_kws={'label': 'Proporção Acolhidos (0-1)'}
)
plt.show()
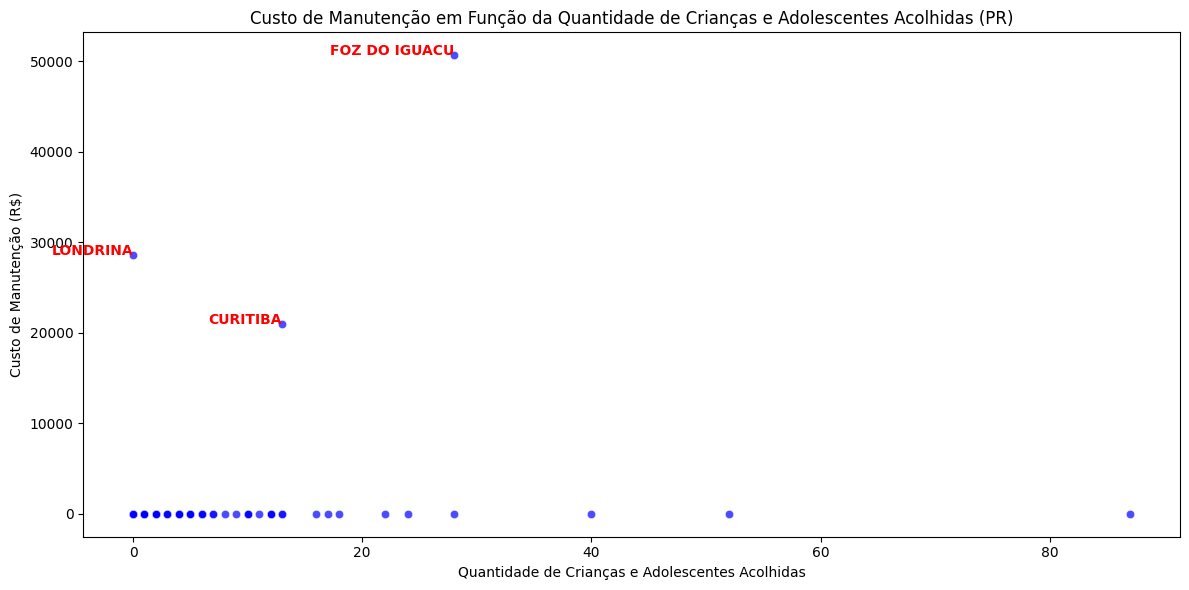
7.2.4. Custo mensal de manutenção#
# Criar uma cópia independente de df_pr
df_pr = df_pr.copy()
# Corrigir os valores em strings com vírgula para ponto
df_pr['custo_manutencao'] = df_pr['custo_manutencao'].str.replace(',', '.')
# Remover espaços em branco (se houver)
df_pr['custo_manutencao'] = df_pr['custo_manutencao'].str.strip()
# Transformar em dados numéricos
df_pr['custo_manutencao'] = pd.to_numeric(df_pr['custo_manutencao'], errors='coerce')
# Alterar os valores NaN para 0
df_pr['custo_manutencao'] = df_pr['custo_manutencao'].fillna(0)
# Selecionar os municípios de PR com maiores custos (Top 3 - únicos com valores válidos)
top_custos_pr = df_pr.nlargest(3, 'custo_manutencao')
# Criar o gráfico de dispersão
plt.figure(figsize=(12, 6))
sns.scatterplot(
data=df_pr,
x='qtd_criancas_acolhidas',
y='custo_manutencao',
color='blue',
alpha=0.7
)
# Adicionar rótulos aos maiores custos
for i, row in top_custos_pr.iterrows():
plt.text(
row['qtd_criancas_acolhidas'], # Coordenada X
row['custo_manutencao'], # Coordenada Y
row['municipio'], # Texto (nome do município)
horizontalalignment='right',
size='medium',
color='red',
weight='semibold'
)
# Configurar o gráfico
plt.title('Custo de Manutenção em Função da Quantidade de Crianças e Adolescentes Acolhidas (PR)')
plt.xlabel('Quantidade de Crianças e Adolescentes Acolhidas')
plt.ylabel('Custo de Manutenção (R$)')
plt.tight_layout()
plt.show()
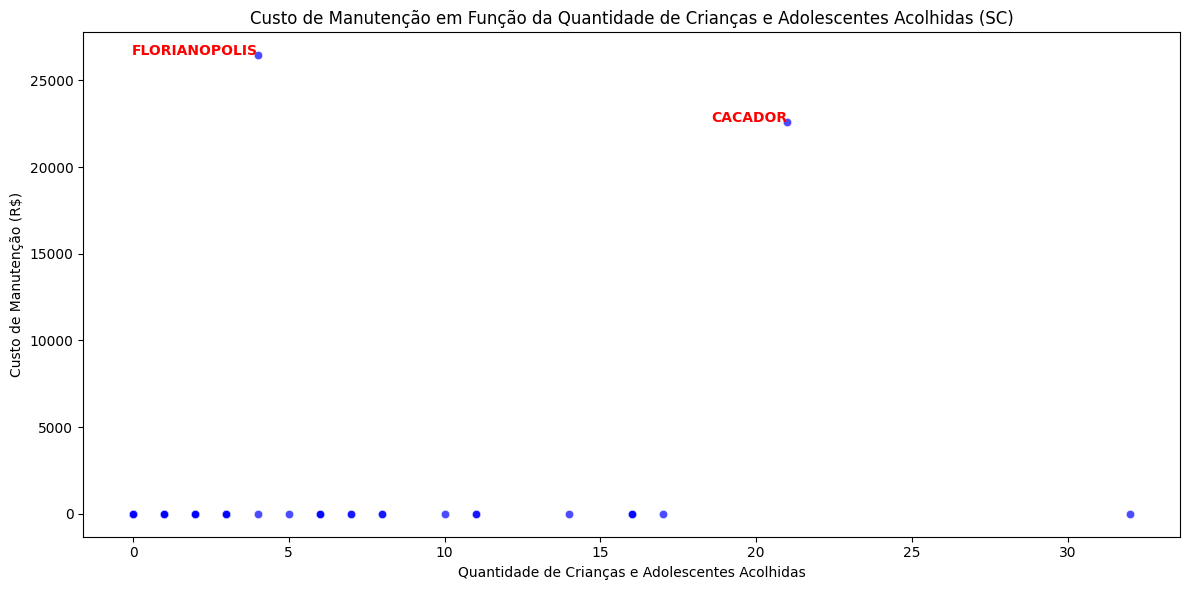
# Criar uma cópia independente de df_sc
df_sc = df_sc.copy()
# Corrigir os valores em strings com vírgula para ponto
df_sc['custo_manutencao'] = df_sc['custo_manutencao'].str.replace(',', '.')
# Remover espaços em branco (se houver)
df_sc['custo_manutencao'] = df_sc['custo_manutencao'].str.strip()
# Transformar em dados numéricos
df_sc['custo_manutencao'] = pd.to_numeric(df_sc['custo_manutencao'], errors='coerce')
# Alterar os valores NaN para 0
df_sc['custo_manutencao'] = df_sc['custo_manutencao'].fillna(0)
# Selecionar os municípios de SC com maiores custos (Top 2 - únicos com valores válidos)
top_custos_sc = df_sc.nlargest(2, 'custo_manutencao')
# Criar o gráfico de dispersão
plt.figure(figsize=(12, 6))
sns.scatterplot(
data=df_sc,
x='qtd_criancas_acolhidas',
y='custo_manutencao',
color='blue',
alpha=0.7
)
# Adicionar rótulos aos maiores custos
for i, row in top_custos_sc.iterrows():
plt.text(
row['qtd_criancas_acolhidas'], # Coordenada X
row['custo_manutencao'], # Coordenada Y
row['municipio'], # Texto (nome do município)
horizontalalignment='right',
size='medium',
color='red',
weight='semibold'
)
# Configurar o gráfico
plt.title('Custo de Manutenção em Função da Quantidade de Crianças e Adolescentes Acolhidas (SC)')
plt.xlabel('Quantidade de Crianças e Adolescentes Acolhidas')
plt.ylabel('Custo de Manutenção (R$)')
plt.tight_layout()
plt.show()
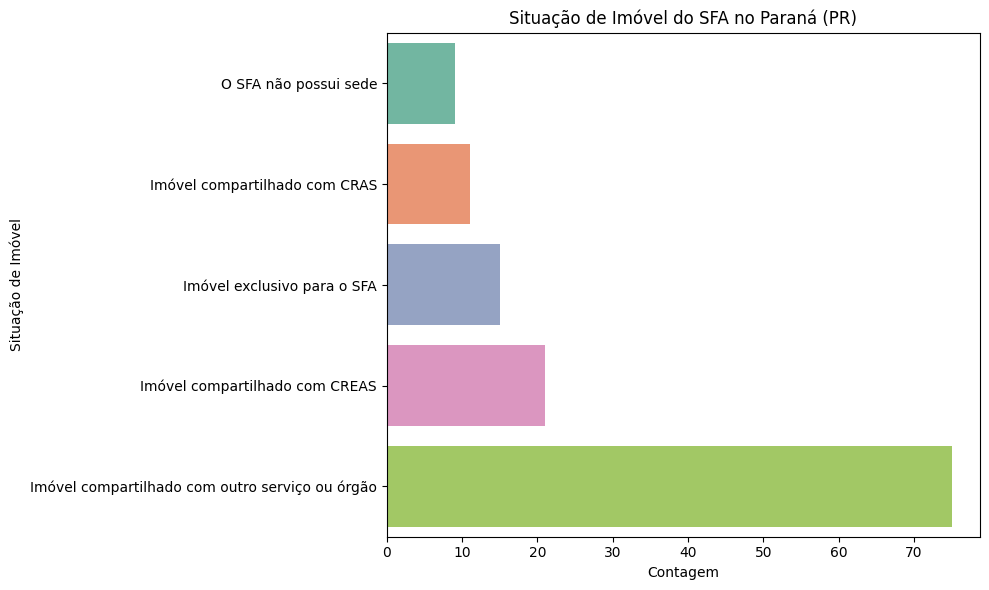
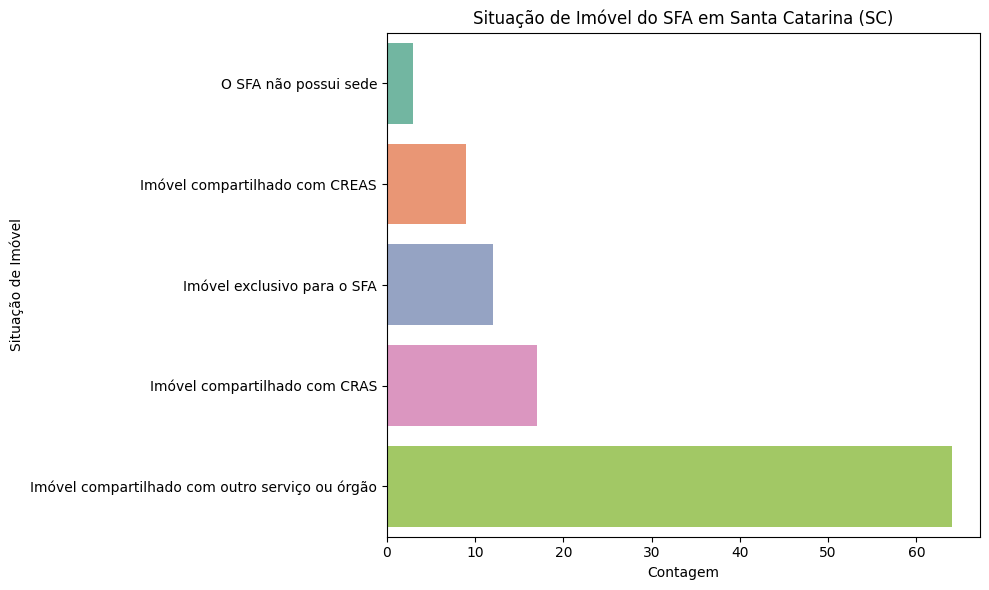
7.2.5. Situação do imóvel onde funciona a sede do SFA#
# Agrupar os dados para o Paraná (PR) por situação do imóvel
df_imovel_pr = df_pr.groupby('imovel_sede_saf').size().reset_index(name='contagem')
# Ordenar os dados em ordem crescente
df_imovel_pr = df_imovel_pr.sort_values(by='contagem', ascending=True)
# Plotar o gráfico de barras para PR
plt.figure(figsize=(10, 6))
sns.barplot(
x='contagem',
y='imovel_sede_saf',
data=df_imovel_pr,
palette='Set2',
hue='contagem',
legend=False
)
# Configurar o gráfico
plt.title("Situação de Imóvel do SFA no Paraná (PR)")
plt.xlabel("Contagem")
plt.ylabel("Situação de Imóvel")
plt.tight_layout()
# Mostrar o gráfico
plt.show()
# Agrupar os dados para Santa Catarina (SC) por situação do imóvel
df_imovel_sc = df_sc.groupby('imovel_sede_saf').size().reset_index(name='contagem')
# Ordenar os dados em ordem crescente
df_imovel_sc = df_imovel_sc.sort_values(by='contagem', ascending=True)
# Plotar o gráfico de barras para SC
plt.figure(figsize=(10, 6))
sns.barplot(
x='contagem',
y='imovel_sede_saf',
data=df_imovel_sc,
palette='Set2',
hue='contagem',
legend=False
)
# Configurar o gráfico
plt.title("Situação de Imóvel do SFA em Santa Catarina (SC)")
plt.xlabel("Contagem")
plt.ylabel("Situação de Imóvel")
plt.tight_layout()
# Mostrar o gráfico
plt.show()
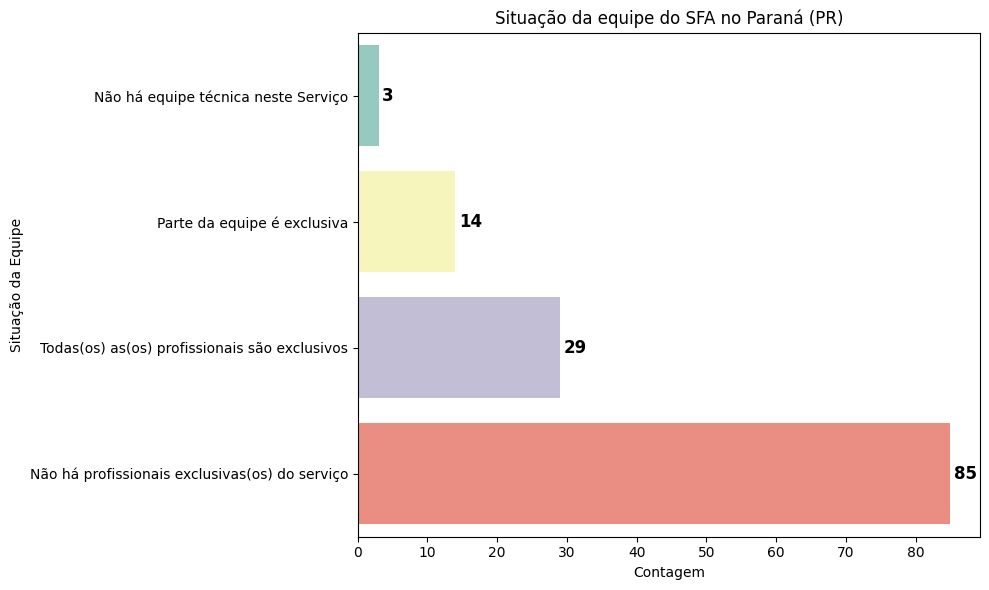
7.2.6. Equipe técnica exclusiva#
# Agrupar os dados para o Paraná (PR) por situação da equipe do SFA
df_equipe_pr = df_pr.groupby('equipe_tec_exclusiva_saf').size().reset_index(name='contagem')
# Ordenar os dados em ordem crescente
df_equipe_pr = df_equipe_pr.sort_values(by='contagem', ascending=True)
# Plotar o gráfico de barras para PR
plt.figure(figsize=(10, 6))
ax = sns.barplot(
x='contagem',
y='equipe_tec_exclusiva_saf',
data=df_equipe_pr,
palette='Set3',
hue='contagem',
legend=False
)
# Adicionar os valores dentro das barras
for p in ax.patches:
ax.text(
p.get_width() + 0.5, # Posicionar o texto ao lado da barra
p.get_y() + p.get_height() / 2, # Centralizar o texto verticalmente
int(p.get_width()), # Valor a ser exibido
ha='left', # Alinhar à esquerda
va='center', # Centralizar verticalmente
fontsize=12, # Tamanho da fonte
color='black', # Cor do texto
weight='bold' # Negrito
)
# Configurar o gráfico
plt.title("Situação da equipe do SFA no Paraná (PR)")
plt.xlabel("Contagem")
plt.ylabel("Situação da Equipe")
plt.tight_layout()
# Mostrar o gráfico
plt.show()
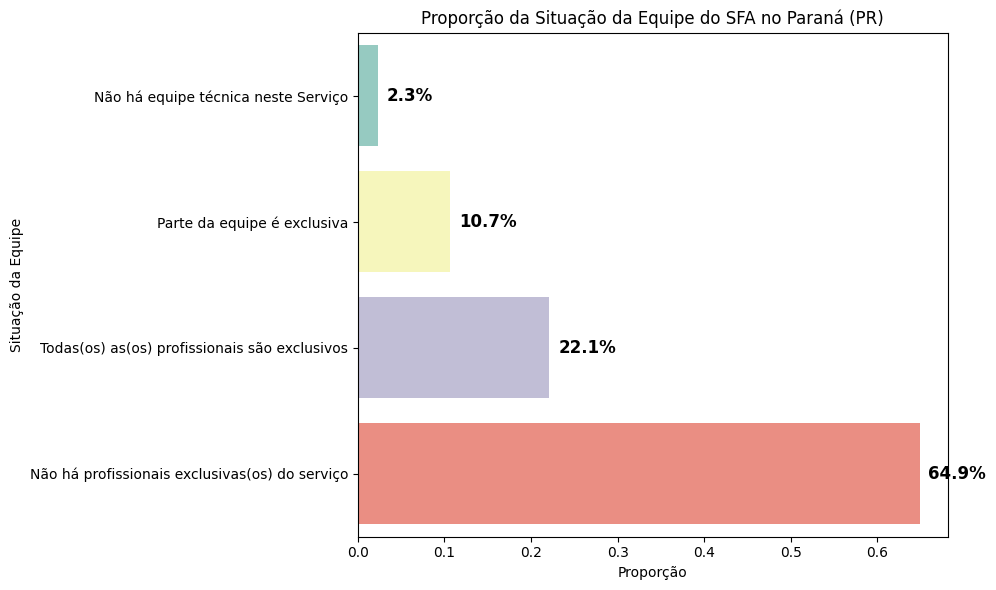
# Calcular a proporção PR
df_equipe_pr['proporcao'] = df_equipe_pr['contagem'] / df_equipe_pr['contagem'].sum()
# Plotar o gráfico de barras para PR (proporção)
plt.figure(figsize=(10, 6))
ax = sns.barplot(
x='proporcao',
y='equipe_tec_exclusiva_saf',
data=df_equipe_pr,
palette='Set3',
hue='equipe_tec_exclusiva_saf',
legend=False
)
# Adicionar os valores dentro das barras (em porcentagem)
for p in ax.patches:
ax.text(
p.get_width() + 0.01, # Posicionar o texto ao lado da barra
p.get_y() + p.get_height() / 2, # Centralizar o texto verticalmente
f"{p.get_width() * 100:.1f}%", # Valor em porcentagem
ha='left', # Alinhar à esquerda
va='center', # Centralizar verticalmente
fontsize=12, # Tamanho da fonte
color='black', # Cor do texto
weight='bold' # Negrito
)
# Configurar o gráfico
plt.title("Proporção da Situação da Equipe do SFA no Paraná (PR)")
plt.xlabel("Proporção")
plt.ylabel("Situação da Equipe")
plt.tight_layout()
# Mostrar o gráfico
plt.show()
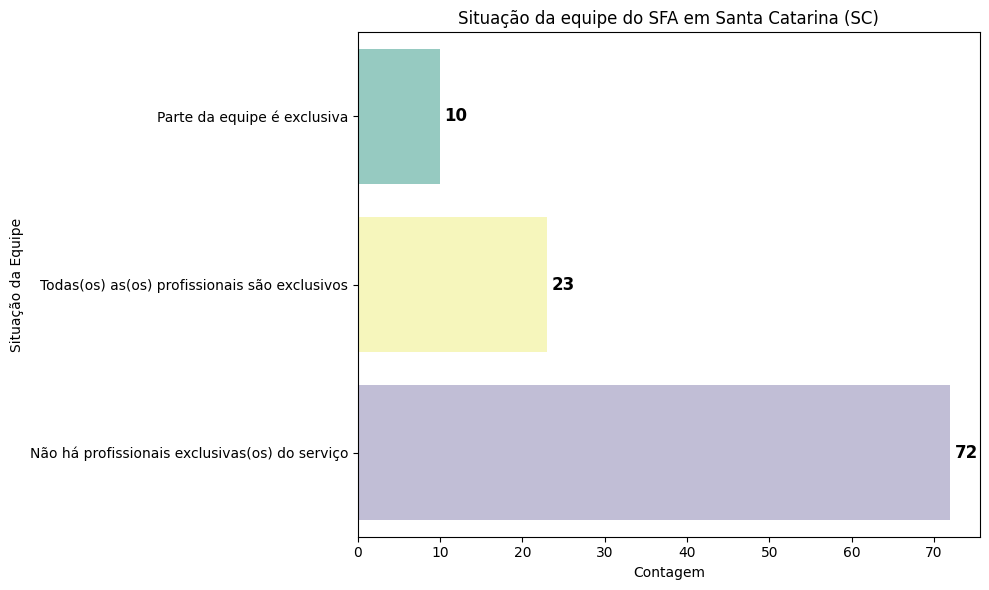
# Agrupar os dados para Santa Catarina (SC) por situação da equipe do SFA
df_equipe_sc = df_sc.groupby('equipe_tec_exclusiva_saf').size().reset_index(name='contagem')
# Ordenar os dados em ordem crescente
df_equipe_sc = df_equipe_sc.sort_values(by='contagem', ascending=True)
# Plotar o gráfico de barras para SC
plt.figure(figsize=(10, 6))
ax = sns.barplot(
x='contagem',
y='equipe_tec_exclusiva_saf',
data=df_equipe_sc,
palette='Set3',
hue='contagem',
legend=False
)
# Adicionar os valores dentro das barras
for p in ax.patches:
ax.text(
p.get_width() + 0.5, # Posicionar o texto ao lado da barra
p.get_y() + p.get_height() / 2, # Centralizar o texto verticalmente
int(p.get_width()), # Valor a ser exibido
ha='left', # Alinhar à esquerda
va='center', # Centralizar verticalmente
fontsize=12, # Tamanho da fonte
color='black', # Cor do texto
weight='bold' # Negrito
)
# Configurar o gráfico
plt.title("Situação da equipe do SFA em Santa Catarina (SC)")
plt.xlabel("Contagem")
plt.ylabel("Situação da Equipe")
plt.tight_layout()
# Mostrar o gráfico
plt.show()
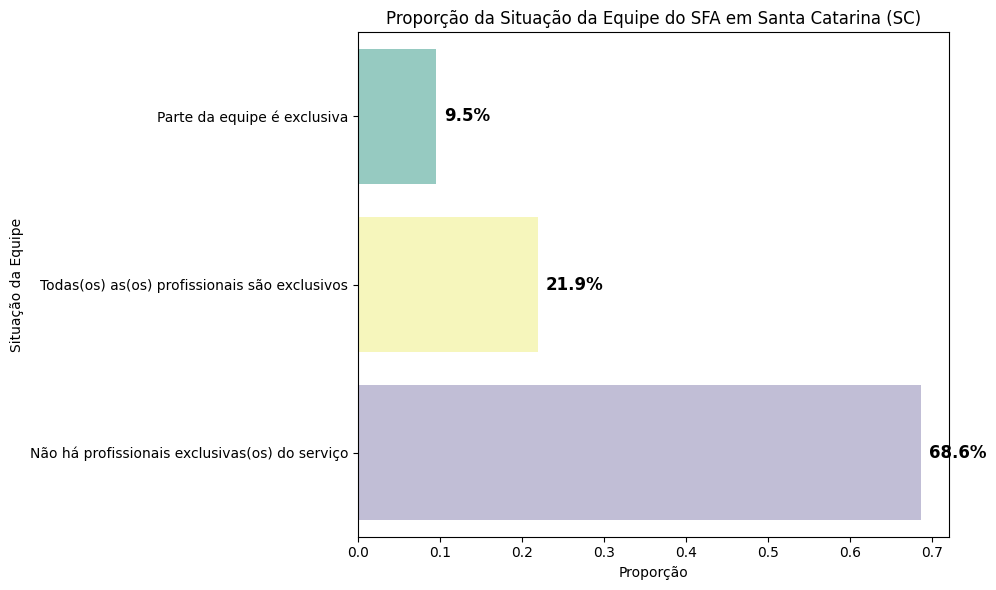
# Calcular a proporção SC
df_equipe_sc['proporcao'] = df_equipe_sc['contagem'] / df_equipe_sc['contagem'].sum()
# Plotar o gráfico de barras para SC (proporção)
plt.figure(figsize=(10, 6))
ax = sns.barplot(
x='proporcao',
y='equipe_tec_exclusiva_saf',
data=df_equipe_sc,
palette='Set3',
hue='equipe_tec_exclusiva_saf',
legend=False
)
# Adicionar os valores dentro das barras (em porcentagem)
for p in ax.patches:
ax.text(
p.get_width() + 0.01, # Posicionar o texto ao lado da barra
p.get_y() + p.get_height() / 2, # Centralizar o texto verticalmente
f"{p.get_width() * 100:.1f}%", # Valor em porcentagem
ha='left', # Alinhar à esquerda
va='center', # Centralizar verticalmente
fontsize=12, # Tamanho da fonte
color='black', # Cor do texto
weight='bold' # Negrito
)
# Configurar o gráfico
plt.title("Proporção da Situação da Equipe do SFA em Santa Catarina (SC)")
plt.xlabel("Proporção")
plt.ylabel("Situação da Equipe")
plt.tight_layout()
# Mostrar o gráfico
plt.show()
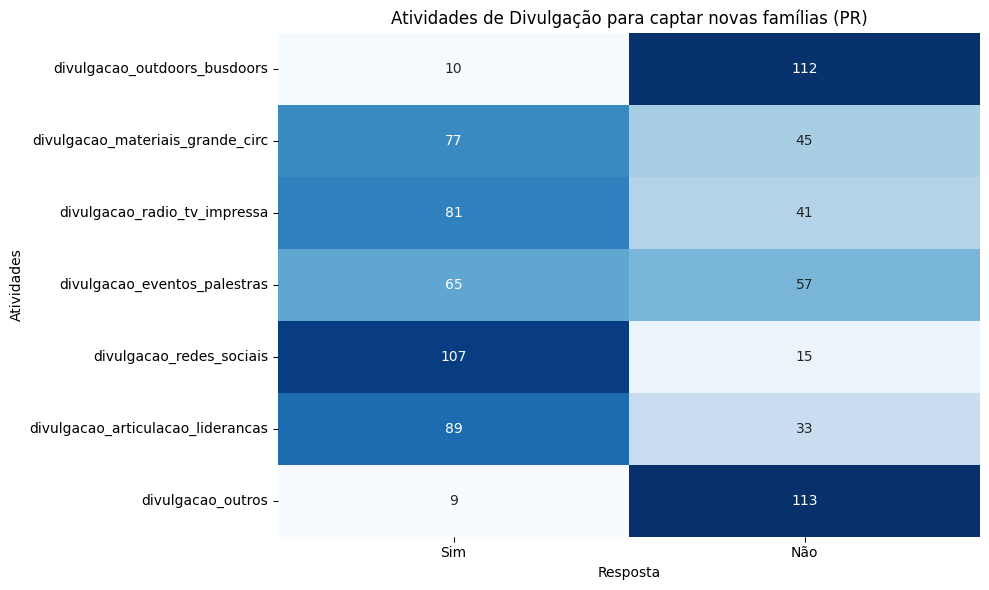
7.2.7. Ações de divulgação#
colunas_divulgacao = ['divulgacao_outdoors_busdoors',
'divulgacao_materiais_grande_circ',
'divulgacao_radio_tv_impressa',
'divulgacao_eventos_palestras',
'divulgacao_redes_sociais',
'divulgacao_articulacao_liderancas',
'divulgacao_outros']
# Filtrar os dados para PR
df_pr_divulgacao = df_pr[colunas_divulgacao].apply(lambda x: x.value_counts(dropna=True)).T
# Gráfico de calor para PR
plt.figure(figsize=(10, 6))
sns.heatmap(
df_pr_divulgacao[['Sim', 'Não']],
annot=True,
cmap='Blues',
cbar=False,
fmt='d'
)
plt.title('Atividades de Divulgação para captar novas famílias (PR)')
plt.xlabel('Resposta')
plt.ylabel('Atividades')
plt.tight_layout()
plt.show()
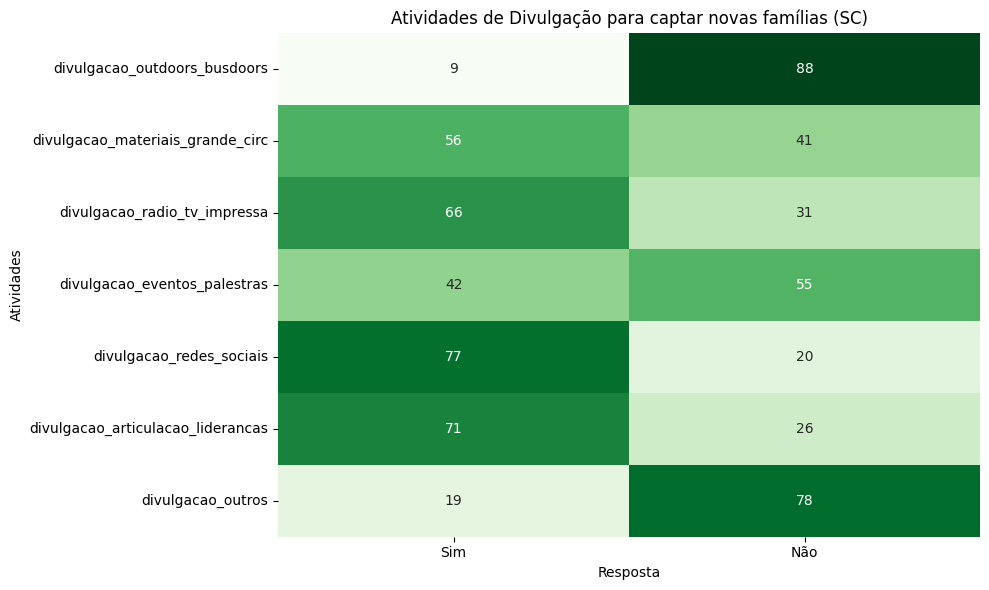
# Filtrar os dados para SC
df_sc_divulgacao = df_sc[colunas_divulgacao].apply(lambda x: x.value_counts(dropna=True)).T
# Gráfico de calor para SC
plt.figure(figsize=(10, 6))
sns.heatmap(
df_sc_divulgacao[['Sim', 'Não']],
annot=True,
cmap='Greens',
cbar=False,
fmt='d'
)
plt.title('Atividades de Divulgação para captar novas famílias (SC)')
plt.xlabel('Resposta')
plt.ylabel('Atividades')
plt.tight_layout()
plt.show()